機械学習による再スコアリングはどのように機能するのか?
Mascot ServerにはPercolatorが搭載されています。 Percolatorは半教師付き機械学習を使用して、正しい/正しくないスペクトルの識別を改善するアルゴリズムです。こういった作業は「機械学習による再スコアリング(rescoring)」と呼ばれます。具体的に何を意味するのか?どのように機能するのか?このブログ記事で掘り下げて説明します。
スコアの同定基準値を使った正しいマッチの識別
ターゲットのタンパク質配列データベースに対して検索を実施すると、正しい(correct)あるいは正しくない(incorrect) ペプチドマッチが混在した結果が得られます。MASCOTを含むすべての検索エンジンにおいて起こります。例えば、正解の配列がデータベースになかったり、スペクトルに含まれる強度の大きなノイズがたまたま間違ってピークとしてアサインされてしまいスコアが良くなる、といった事が起こります。
MASCOTのion scoreなど検索エンジンのスコアというのは、正しいマッチのスコアが高くなり、正しくないマッチのスコアが低くなるよう設計されています。そして、スコアの同定基準値を設定することで、不正確なマッチのほとんどを捨て、正しいマッチのほとんどを残すことができます。
しかし残念なことに現実のデータセットでは、1つの(単一次元での)評価・スコアリングでプロットした場合、マッチングの正誤がきれいに分かれることはほとんどありません。
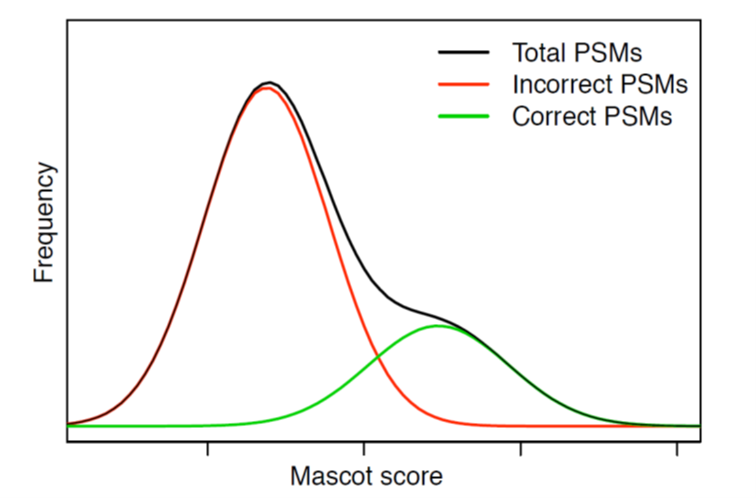
上の図式は特に悪いケースを示しており、正しいマッチのほとんどが、正しくないマッチと同じ範囲でのスコア分布となっています。スコアの同定基準値をどこに設定しても、多くの正しいマッチを失うか、多くの不正確なマッチが含まれる事になるのです。
複数次元のスコアリング
機械学習による再スコアリングとは、母集団を分離するために複数の次元を使うことを意味します。この手法が有効であるのは、正しくないマッチはしばしば正しいマッチと体系的に異なることが多いためです。
MascotでPercolatorを有効にすると、データベース検索の最後にMascotが、各ペプチドのマッチングに対して様々な「フィーチャー(訳者注 : feature,特徴。「抽出されたある特徴を表す数値」の意味)」を計算します。各フィーチャーの数値はPercolator InPut (pip) ファイルに保存されます。フィーチャーの1つはMascotのイオンスコアそのものです。そのほかのフィーチャーの例として、例えばプリカーサーの質量誤差などが挙げられます。正解のマッチングは0に近い誤差を示す傾向があるのに対して、不正解のマッチングはランダムな数値を取る事が多いためです。その他、電荷の状態、ミス切断の数、マッチしたフラグメントイオンの強度の割合などがあります。
ターゲット - デコイ検索の目的
Percolatorのような半教師付き機械学習を利用するためには、正しいペプチド同定と誤ったペプチド同定のラベル付けされたデータが必要です。そのようなラベル付けを検索エンジンのスコアだけで行う事ができません。(もしそれができるのであれば、そもそも機械学習を適用する必要もありません!)。
その解決法となるのがターゲット-デコイ検索と呼ばれる手法で、既にプロテオミクスの研究者にはお馴染みのものです。基本的にはターゲット配列データベースに対して検索を実行する際、逆配列またはランダム化した「デコイ」タンパク質の配列に対しても検索を実行します。そしてデコイデータベースでマッチした内容を「正しくないマッチ(incorrect match)」であると定めます。デコイデータベースはターゲットデータベースと統計的な特徴が類似(訳者注 : データベースに含まれるタンパク質の長さや質量の分布が似ている、という意味で)しているため、デコイデータベースへのマッチング内容は、ターゲットデータベースの不正確なマッチをモデル化したものと仮定する事ができるのです。
デコイマッチは半教師付き機械学習のための「ネガティブ(不正解)」な例として扱います。一方、ターゲットデータベースでのマッチはネガティブとポジティブ(正解)の未知の混合となります。Percolatorは、最初に高得点のターゲットマッチを「ポジティブ」例として選択し、多次元空間においてネガティブとポジティブの最適な分離が可能な基準が見つかるまで、繰り返しモデルを学習させ続けます。
多次元スコアのしきい値
Percolatorは、各ペプチドのマッチについてq値と事後誤差確率(PEP)を計算します。これは過去の論文、事後誤差確率と偽発見率 (Posterior Error Probabilities and False Discovery Rates) において詳しく説明されています。再スコアリング後、MascotはPEP値を確認するとともに、ターゲット検索におけるFDRの条件に合うPEP閾値を計算します。このようなプロセスで多次元性(多数のフィーチャー)を1つの数値(PEP)に凝縮して新しい同定基準値を得ます。

上のヒストグラムは、Percolatorによる再スコアリング後の例です。青がターゲットペプチドとのマッチ、赤がデコイとのマッチです。間に引かれた破線が1%のFDR閾値です。誤ったターゲットマッチ(破線の左側、赤に重なった青)と正しいターゲットマッチ(破線の右側、青)の間で、非常に明確な分離が見られます。
ターゲットデータベースの高スコアマッチにおいては、再スコアリング前後の結果を比較してもその中身はほとんど同じです。通常改善されるのはMascotスコアが中程度のマッチです。計算されたフィーチャーが高品質の「ポジティブ(正解)」なデータと類似している場合、すなわちフィーチャーの多次元空間において一緒にクラスタリングされている場合、スペクトルのマッチングが十分とは言えないデータもポジティブと判定されます。機械学習が検索エンジンのスコア以外の追加情報を利用して判断していると言えます。
上記のヒストグラム図はMascot Serverの次のバージョンで利用できるようになります。また2つの母集団を分けるのにどのフィーチャーが最も影響を与えたかについて、より詳細なレポートをユーザーに提示できるようにする予定です。
Mascotにおいてこれらの解析を行う方法
MASCOTにおいて再スコアリング機能を有効にすると、ペプチドの同定数が増えることがよくあります。例えば内因性ペプチドの解析(英語版、日本語版)を過去にご紹介しました。デフォルトで、Percolatorの利用が有効になるように設定する事もできます。
Mascot検索を実行する際、私たちは常にデコイデータベースへの検索実施も併せて行うよう、お勧めしています。Mascot Serverの次期バージョンでは、デコイ検索の実行がデフォルト設定になります。
またmascot.dat内にあるオプションの設定を変更することで、Percolatorの利用がデフォルトで有効になります。具体的には以下のオプションです。
Percolator 1
出荷時のデフォルトは0で、有効になっていません。また検索後に表示される結果画面、Protein Family Summaryレポートのフォーマットコントロールでも、Percolator適用の有無を切り替える事ができます。
私たちは、解析データに合っていない場合は機械学習の適用を控えた方が良いと考えています。例えばTarget検索におけるマッチの数がとても少なかったり、デコイマッチの数が少なすぎたり、マッチの質が十分でない場合、良い結果になりません。モデルが収束するような状況であればPercolatorが結果を悪化させることはほとんどありませんが、機械学習を適用する/しない、という切り替えによって結果にどの程度の違いがあるかを理解することは重要です。
機械学習ではできないこと
機械学習そのものは、適切な統計的スコアリングによりペプチド配列を決定するプログラムの代用にはなりません。 昔からの格言「garbage in, garbage out」を思い出してください。最初に何かしらの方法(mascotのスコアリングなど)によって、半教師付き機械学習を開始するのに十分な識別情報を提供しなければなりません。質の低いPSM(ペプチドスペクトルマッチ)を魔法のように質の高いPSMに変えることはできません。データベースの検索結果が良ければ良いほど、機械学習も良くなります。
また、再スコアリングはデータベースにないペプチドの発見には使えません。トレーニングの段階で新しいペプチドを「発明」するわけではないからです。検索エンジンが提供するペプチド同定結果を使うにすぎません。さらに、適切な配列データベース、適切なfixedおよびvariable修飾設定、酵素およびミス切断など、検索スペースが過不足ない事を確認することが、これまで同様に重要です。
Keywords: FDR, Percolator, scoring