
今月ミネアポリスで開催されたASMSでは多くの方にお会いすることができました。ユーザーミーティングではMascot ServerおよびDistillerの最新の開発状況を説明しましたが、見逃した方は、スライドとスピーカーのメモを記したパワーポイント資料を以下に掲載しますのでそちらを是非ご覧ください。
今月の論文は、スプライスアイソフォームをより良く同定するためにロングリードRNA-seqをMASCOTのタンパク質データベースとして利用する方法を紹介しています。
今月の小技は、FDR (False Discovery Rate)に関する考察です。
Mascotニューズレターのバックナンバーはこのページ(英語版、日本語版)からご覧いただけます。また、Mascotニューズレターの内容に関してお気づきの点やご質問などありましたらご連絡ください。

Mascot ServerおよびDistillerの最新バージョンでは、多くの改善が行われました。ミネアポリスで開催されたASMSユーザーミーティングのプレゼンテーションでは、その新機能についていくつかご紹介しています。
講演タイトルをクリックすると、スライドと講演者のメモを含むPDFが表示されます。是非ご覧ください。
NCBIprot、mzIdentML 1.2,…: Mascot Server 2.8.1の改良点
発表者 Ville Koskinen (Matrix Science)
発表者 Richard Jacob (Matrix Science)
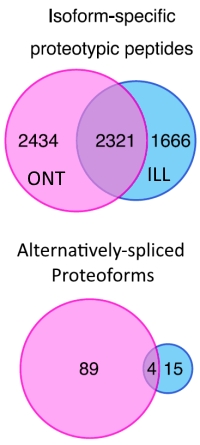
Aidan P. Tay, Joshua J. Hamey, Gabriella E. Martyn, Laurence O. W. Wilson, and Marc R. Wilkins
J. Proteome Res., published online May 25, 2022
Alternative splicingは、コード領域と非翻訳領域の遺伝子上の位置と組み合わせが異なる転写産物をもたらし、異なる機能を持つ可能性があるタンパク質のアイソフォームを生み出します。Alternative splicingにより生み出される機能的に重要ながらも未知なタンパク質を同定するため、著者らはロングリードおよびショートリードのRNAシーケンスデータのデータベースとしての利用とその検索結果を比較し、独自のタンパク質データベースの構築を検討しました。ショートリードRNA-seqでは通常遺伝子内の複数個所にマッピングされ複数のスプライスジャンクションにまたがってコードされている事はあまりないですが、ロングリードRNA-seqを使用する事でタンパク質アイソフォームの同定数が増えるはずであると彼らは仮定しました。
彼らはProteomeXchangeから入手したヒトK562細胞のプロテオームデータセットを入力データとして使用しました。また検索対象のデータベースとして、(1)Illuminaから得たショートリードRNA-seq由来のデータ、(2) Oxford NanoporeのロングリードRNA-seq 、それぞれから構築したタンパク質配列データベースで検索を行い、結果を比較しました。
両データベースには、互いのデータベースでしか同定できないケースが多く見られました。long-readデータベースによる検索でアイソフォームに特異的なプロテオタイプペプチドが4755個、short readデータベースでは3987個が同定され、そのうち共通するペプチドは2321個でした。 またalternative splicingによって生じるタンパク質アイソフォームについて、Ensembleの情報に基づいた解析を行ったところ、ロングリードのデータベースでは39遺伝子から93タンパク質アイソフォームが、ショートリードのデータベースでは10遺伝子から19タンパク質アイソフォームが検出され、共通しているタンパク質は4つでした。
Mascotニューズレターで取り上げてほしい話題や研究論文がありましたらぜひご紹介ください。また、Mascotニューズレターの内容に関してお気づきの点やご質問などありましたらご連絡ください。
ウィキペディアの情報によると、アメリカの平均人口密度は1平方キロメートルあたり約36人です。数学がよほど苦手な人であっても、この数字がある特定の地域にのみ焦点を当てた際にも常に成り立つ数ではないという事はお分かりいただけるはずです。大都市での人口密度は平均値より数段高いでしょうし、一方アラスカやデスバレーではもっと低くなるはずです。
現在ペプチド同定で使用されているFalse Discovery Rateにも実は同じ話が当てはまるのですが、こちらは直感的でないせいかあまりその事を認知されていません。FDRの数値はあくまでも「平均的な値」です。target-decoy手法を駆使してグローバルなFDRを正確に1%に調整することはできますが,長いペプチドや短いペプチド,variable modificationの修飾がマッチしたペプチドなど、特定条件に着目してみるとglobal FDRとは大きく異なる数値になります。
過去に発表した一連のブログ記事で、関連事項も含めこの問題について議論するとともに様々な種類の属性に着目しtargetとdecoyでの違いを見ています。例えばFDR1%で検出された検索結果の中でvariable modificationが当たっているペプチドに注目すると、通常データベース側ではマッチ全体の3%のみを占めるのに対し、decoyデータベースとのマッチにおいては41%となり対照的です。修飾ペプチドや非特異的切断パターンのペプチドに着目した解析を行いたい場合、FDRの計算にすべてのペプチドに着目した数字ばかりを見るのでなく、着目した内容でまとめたペプチドのみをカウントの対象にした数字も検討する必要があります。
マトリックスサイエンス株式会社
〒110-0015
東京都台東区東上野1-6-10 ARTビル1F
電話:03-5807-7895
ファクシミリ:03-5807-7896